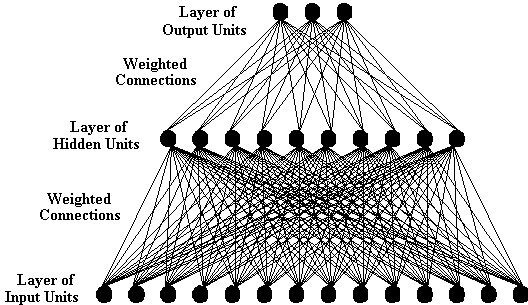
That figure (which I stole from this website) is pretty self-explanatory, right? I can probably just leave it at that and say nothing more. OK, maybe if I add this one (from the same website):
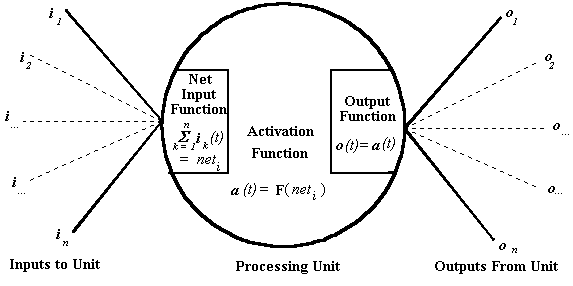
There, that should do it. Can you tell I'm not overly excited about the prospect of talking about connectionism? It reminds me of my undergraduate course in matrix algebra, among other unpleasant things. But I'll suck it up and get on with it.
Actually, most of what you need to know really is contained in those diagrams. Connectionist models are essentially pattern detectors. They involve layers of units that send signals to each other (in the simplest case, the signals only move in one direction, but in more complex models, they can go backwards and forwards), with the aim of producing an output pattern that corresponds to the input pattern the model received. In the simplest models, there are three layers of units: a layer of input units, a layer of hidden units (the second diagram calls a unit in this layer a "processing unit"), and a layer of output units. Between the three layers are connections, running from the input layer to the hidden layer, and from the hidden layer to the output layer. There are two important features of the connections: their sign and their strength, or weight (in more complex models, the direction that the signal moves on a connection is also important). A connection with a positive sign is excitatory, i.e., when a signal is sent down that connection between two units, it increases the level of activation in the receiving unit; a connection with a negative sign is inhibitory, which just means that a signal sent down it decreases the level of activation of the receiving unit. The strength of a connection determines how much the activation level of the receiving unit is increased or decreased by a particular signal. In simple models, the strengths usually vary between 0 to 1.
As the second figure above indicates, even in a simple model, things are a little more complicated than the last paragraph made them out to be. This is because a unit in the hidden layer or output layer generally doesn't receive one signal from one input unit. Instead, it receives a bunch of signals at the same time from multiple input/hidden layer units, and it has to combine them in some way to determine how active it should be. In the simplest models, the receiving unit just sums all of the signals it receives at one time, and then computes an activation level. If the sum of all is inputs are positive, it will become more active for a period of time (the activation function in the second figure usually contains within it a decay function that determines how long it will stay active after receiving input), and if it is negative, it will become less active. You can think about the units as neurons which are just minding their own business, firing away at their baseline rates (the rates they fire when they're not receiving any signals), when all of the sudden a rush of input from several other neurons comes in. Some of the input is excitatory, and some of it inhibitory, so the neuron has to combine all of the signals from multiple other neurons together, and if the net input is excitatory, it raises its activation level above the baseline, while if it is negative, it drops its activation level below the baseline. After a short time, if it doesn't receive any more input, it will return to the baseline (or below the baseline, if it was excited and there is a refractory period). Of course, the units in connectionist models aren't neurons, so they don't actually fire, and they don't really have a resting level. Instead, the level of activation of a unit in a model determines how strong the signal it sends down stream to the next level of units will be.
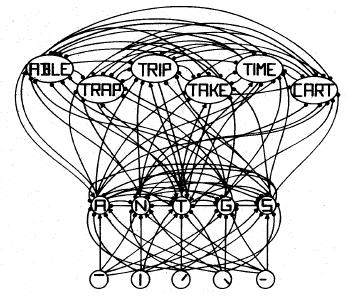
Consider an example model. If you've ever taken a course in cognitive science, you've probably seen this third figure. It's from a classic paper by McClelland and Rumelhart1 on perceiving letters and words. At the bottom are the input units, which detect oriented lines in the first letter of a word that the model receives as input. In the middle are the hidden units which represent the possible first letters. Take, as an example, the T unit (the one in the middle of the hidden layer). When the upper horizontal line input unit (far left) and the vertical line input unit (second from the left) are activated, they send excitatory signals to the T unit. When the angled line input units (middle and second from right) are activated, they send inhibitory signals to the T unit. The other hidden units work the same way (but with the excitatory and inhibitory connections coming from the input units with the components of their letters). The hidden units then send a signal to the output units, based on how active they've become. These signals also have connection weights and signs. The output units work pretty much like the hidden units. The output that wins and gives the models "answer" is the one that ends up with the highest sum of input signals from the hidden units. Obviously, to get whole words (like in the model above), you have to have input units, and perhaps hidden units, for the letter in each position in the word, and the winning output unit gets the most activation from all of those units.
So that is a highly oversimplified explanation of how a connectionist model recognizes a pattern (in this case, a word). But at the start, a model can't recognize any patterns. It has to be trained. To do that, you have to include some method for giving it feedback, and for that feedback to affect the connection strengths between the different layers. First, you randomly assign connection weights between each of the nodes. Then you give the model an input. Inevitably, the output will not be the desired input (the pattern the model is supposed to recognize), so you adjust the weights on each of the connections. The simplest way to do this is to compare each weight to the weight that would yield the correct pattern, and adjust the weight based on the difference. After a lot of training, this method will leave you with a model that can recognize the patterns on which it was trained with a high degree of accuracy. Some models can even generalize to novel patterns (e.g., new words with the same letters that were used to train the model).
In more complex models (which would include most of the models used today), things get, well, more complex. The simple model I described above is a strictly feed-forward model: the input layer sends signals to the hidden layer, which sends signals to the output layer. However, other models use recursion to allow forward layers to influence backward layers. Some also include another type of layer, a "context layer," that receives input from the hidden layer and records the state of that layer at a given time. When another set of inputs comes in to the hidden layer, the context layer then sends a signal back to the hidden layer. Thus the hidden layer's last state serves as the "context" for its interpretation of the new input. Here's a diagram of such a model (from this paper):
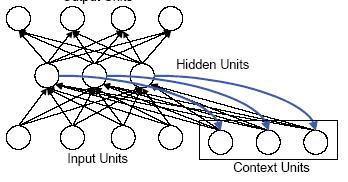 As you can see, the context units have two different kinds of connections: those coming in from the hidden units, which will have one set of connection strengths, and those going back to the hidden units, which will have another set of connection strengths. Things can get pretty messy, mathematically, when you include this and other sorts of recursion in a network. God knows, I can't do the math.
As you can see, the context units have two different kinds of connections: those coming in from the hidden units, which will have one set of connection strengths, and those going back to the hidden units, which will have another set of connection strengths. Things can get pretty messy, mathematically, when you include this and other sorts of recursion in a network. God knows, I can't do the math.When you look at these models (the simple or the complex) more formally, what you will see is that deep down, they don't really look like the above figures. Instead, the connection strengths and weights are represented as vectors in a multidimensional space (a state space, or vector space -- hence the matrix algebra that makes me shudder). Individual patterns occupy a part of that space. This allows you to use connectionist models to do all sorts of things, like determining the similarity of different patterns. The closer together two patterns are in the space, the more similar they are. It also leads to problems, because spatial representations are somewhat limited. What connectionist models, and spatial representations, can do, and perhaps cannot do, or at least cannot do without looking a lot like their alternatives, the symbolic models, has caused a great deal of debate over the utility and epistemological status of connectionist models over the years (see this article for a short account of the controversies).
But you won't need to know anything about that to understand what connectionism means for moral psychology. Hopefully what's in the preceding paragraphs does give you what you need to know for that. I'm sure you can already guess the basic idea: when you get down to it, moral judgment is just a form of pattern recognition. That makes it sound very noble, doesn't it?
1 McClelland, J.L., & Rumelhart, D.E. (1981). An interactive activation model of the effect of context in letter perception: Part 1. Psychological Review, 88(5), 375-407.
9 comments:
So are the connectionists models still big business in cognitive science? I remember doing some simple programming along those lines back in the early 90's, hearing that it was the latest big AI breakthrough, and then hearing little more about it outside of a few niche applications. (In those niches it was obviously very important, but I think Bayesian methods ended up being more useful as often as not)
Yeah, connectionist models are everywhere, these days. I'm not sure there's really any threat of them pushing symbolic models out of cog sci entirely anytime soon, but connectionism is definitely here to stay.
As a connectionist I'd say it's alive and well :-)
Theres some cool new stuff, like Jay McClelland and Timothy Roger's Semantic Cognition book that would be worth checking out if you are interested in where connectionism has gone.
As a connectionist, I'm sure you recognized that third diagram.
I was really impressed with Semantic Cognition, and I'm not even a big fan of connectionism. It might be a good book to read for the reading group somewhere down the line.
Have you read Gary Marcus' The Algebraic Mind? Apparently, he argues for a synthesis of symbolic and connectionist architectures. It's on the list for a local AI reading group I've joined this fall, and I'm very curious about it...
p.s., I'm enjoying Tomasello so far
Cheers,
Joel
Semantic Cognition might be a bit heavily-academic for the reading group. It's really just a 400 page paper, which is why I didn't nominate it in the first place.
But yeah, I liked it so much I'm writing up a paper with Jay McClelland expanding on the model of induction they offer in it in response to some critisicms of it by Josh Tenenbaum and the Bayesian modeling people at MIT.
The Algebraic Mind would make a good reading group book, though. Plus maybe a post on the very-cool work of Paul Smolensky on language in a symbolic/connectionist framework.
Yeah, I was thinking of it as a down-the-line when people are digging into the field sort of thing.
Of course, if we read a book on connectionism, you know who I'd ask to post about it, right?
Jay McClelland? :-)
Ha!
Post a Comment