What is an agent-based model (ABM)? Here's the definition from the TiCS paper (on p. 3 of the pdf version linked above):
[ABMs] build social structures from the "bottom-up," by simulating individuals by virtual agents, and creating emergent organizations out of the operation of rules that govern interactions among agents.ABMs model the behaviors of groups of individuals by creating individuals (agents) with internal rules for processing information, and having them interact (transfer information) using another set of rules. The difference between these models and those we usually see in cognitive science concerns the focus. In ordinary cog sci models, including ordinary connectionist models, the focus is on the internal processing of information by individuals. In ABMs, the focus is on the interactions between individuals, though the effects that these interactions have on the internal processing of information is of interest to some modelers. ABMs have been used to explain all sorts of social phenomena, from the general, such as innovation and collective action, to the particular, such as promotion in university departments. The model I'm going to describe explores the development of a lexicon in a community.
The problem the model, created by Edwin Hutchins and Brian Hazelhurst1, addresses is how a shared set of symbols (e.g., words) arises in a community. It's not designed to fully explain how this occurs, but to demonstrate that, under relatively controlled conditions, a particular theory of distributed cognition described in Hutchins' book Cognition in the Wild. The theory includes six assumptions that are relevant to the model :
- The no telepathy assumption: In order to influence each other, minds must use something external to them.
- The cultural grounding of intelligence assumption: The organization of minds comes about only through the interaction with other individuals in a shared environment.
- The shallow symbol assumption: The nature of mental representations must be explained.
- The material symbols assumption: All symbols, whether they facilitate intra-individual communication or are designed to aid an individual's cognition (e.g., in the form of written memory aids) have a material component, along with the "ideal" component.
- The distributed information-processing assumption: "Cognition can be described as the propagation of representational state across representational media that may be internal to or external to individual minds." (p. 164)
- The no developmental magic assumption: The same processes characterize cognitive operations and the development of those operations.
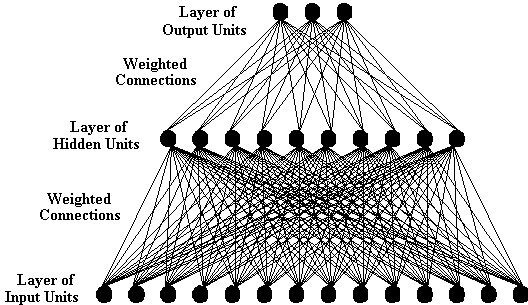
To this sort of architecture, H&H added a twist. The output units still produced the output for the individual agent, but the representations in the hidden layers became public. These representations constituted the "material" symbol for the model; they were, in essence, verbal communication. In addition to outputting their representations to other agents, the hidden units (which are no longer really hidden) also received input from the hidden units of other agents in the form of error correction (see the previous post on connectionism to see how this sort of correction works). Thus, the hidden layer allowed an individual agent to be a speaker, when it shared its representations, or a listener, when it took as feedback the output of the hidden layer of another agent (who in that case served as the speaker). Thus Hutchins and Hazelhurst renamed the hidden layer the "Verbal Input/Output" layer.
The usual input and output layers were also renamed. H&H treated them as a simple visual system, which takes as input a visual scene, and outputs a representation that bears a 1:1 correspondence with that scene (in fact, the output representation was identical to the scene, making the network an autoassociator, for the connectionists out there). So the input and output layers were renamed the visual input and visual output layers respectively. This gives us a system that looks like this:
 This figure represents the network for agent A. A1, A2, and Am represent the verbal outputs (you can think of them as words) for A for each of the scenes (Scene 1, Scene 2,... Scene m). The system is designed to categorize the verbal input and produce a different verbal output for each scene. This allows each symbol to have a "meaning," or a relationship with an individual scene.
This figure represents the network for agent A. A1, A2, and Am represent the verbal outputs (you can think of them as words) for A for each of the scenes (Scene 1, Scene 2,... Scene m). The system is designed to categorize the verbal input and produce a different verbal output for each scene. This allows each symbol to have a "meaning," or a relationship with an individual scene.So they create a bunch of individual agents, and give all of the connections between the different units random values, which means that the individual agents will each produce different verbal outputs for the scenes. Each agent is given 36 visual input units, and 36 visual output units, along with 4 verbal input/output units2. They then ran simulations in which a visual scene, which represented one of 12 possible phases of the moon, is presented to two agents at a time. One agent serves as the speaker, and sends its verbal output to the other agent, called the speaker, which takes it as its verbal input. The listener then uses this verbal input to alter the representation that its own verbal input/output units produced for the scene. In this way, the two agents move closer towards a consensus about how to verbally represent that particular scene. They do this over and over again for thousands of trials in which the speaker and listener are determined randomly, so that each agent views each scene with each other agent as both a speaker and a listener at least once.
After running this simulation, along with a simpler one (with fewer scenes), they found that individuals do indeed converge on a shared set of verbal outputs for each scene. In other words, the community of agents develops a shared lexicon. They also found that community size was important in some situations. When there were a large number of agents, and a new agent was added after the original agents were well on their way to acheiving consensus, the new agent had trouble learning the community's lexicon, but the community's lexicon remained relatively intact. H&H believe that this indicates that a system that is organized in a way that is inconsistent with the shared lexicon of a community will have trouble learning that lexicon. They argue that this may indicate one of the reasons for the existence of a critical period for language learning in humans. Early in development, the brain is organized in a relatively unstructured way, as were the networks of the agents before they began to interact. After a significant period of learning, however, the mind becomes highly structured, and if that structure is inconsistent with the structure of the lexicon (e.g., if a person has learned one language as a child and then must learn another in adulthood), it may be difficult to learn the new structure. They also found that when communities were small, the introduction of a new member could wreak havoc with the developing consensus among the original community members, and the community subsequently had a difficult time developing a shared lexicon. This may be another reason for the existence of critical periods. It allows those who've learned the shared lexicon to avoid being influenced by the input of new members (especially children), which prevents the new members from causing problems with the consensus developed among earlier members. They also created simulations in which dialects developed. In these simulations, the likelihood that a listener would use the verbal input from a speaker depended on how similar that input was to the representations that the listener's own verbal input/output layer produced. When they did this, more than one lexicon developed within the community, which H&H described as dialects.
But the main point of the model was to show that a community of communicating individuals could create a structured system of shared symbol-world relationships where no system had previously existed. This implies that the creation of meaning is a social phenomenon that occurs through the interaction of multiple agents in a shared environment. Interestingly, in their simulations, each of the agents developed different internal representations of the visual scenes. This indicates that agents need not have the same internal representations in order to be able to communicate with each other. Shared symbols that represent aspects of the world are made possible through the interactions of individuals over time, rather than through a shared internal structure. This may have a lot of implications for how we view the nature, use, and learning of language and meaning. Here is how H&H conclude the chapter:
Within this theoretical framework, we claim that meaning can be retrieved from the unattractive positions of being equated with: (a) the results of a (usually innate) private language of mental symbols which stand for an uncontested, fixed, and nonsocial objective reality (Fodor 1976; cf. Lakoff 1987), or (b) an unproblematically shared, static (i.e. a nondevelopmental, nonhistorical, and often nonsocial) semantic knowledge base (ethnoscience and much of cognitive anthropology; cf. Hutchins 1980), or (c) a strictly public (i.e. superindividual, nonmental) symbol system (Geertz 1973; cf. Shore 1991). Meaning in our model is an evolving property of the interaction of internal, artificial [i.e. symbolic - Chris], and natural structures. At any point in the evolution of such a system we take meanings to be characterizations of the functional properties of individualsÂ’ viz.-a-viz. the environment (including each other). Meaning, for each individual, describes a range of possibilities for action.Anyway, this is one way that researchers in cognitive science are now using connectionist architectures. It's not the most common use, but it's certainly an interesting one. Such uses challenge the way we think about cognition, in that they show how it depends both on the individual agent and the community of agents in which the individual exists, and in doing so, they ultimately challenge the way we view ourselves.
1 Hutchins, E. & Hazelhurst, B. (1995). How to invent a lexicon: The development of shared symbols in interaction. In Gilbert, N. & Conte, R. (eds.) Artificial Societies: The Computer Simulation of Social Life p. 157-189: UCL Press.
2 In the process of running the simulation, they learned that 1 hidden layer (the verbal input/output layer) wasn't enough, so they added another. This doesn't really change much for the purposes of a blog explanation, though.
4 comments:
this might be an illusion, but it swear the font underneath your last blockquote is smaller than the stuff above.
It's not an illusion. It's blogger. It put like 50 font changes in there, and I couldn't get rid of them.
This is interesting stuff that I hadn't really seen before. And it goes well with Tomasello's idea of language learning being based largely or entirely on understanding of other's intentions rather than an innate/constrained module.
Tim, right. That's really why I posted it, though I think it is an interesting use of connecionist networks.
Post a Comment